Самым необходимым и востребованным товаром в наше время выступает информация. Выход из строя сервера может привести к тому, что Вы будете лишены возможности получить доступ к информации, и как следствие, произойдет потеря рабочего времени и невозможность быстро реагировать на потребности бизнеса. Кластерные системы высокой готовности позволяют избежать простоев в работе, когда выходит из строя аппаратный сервер.
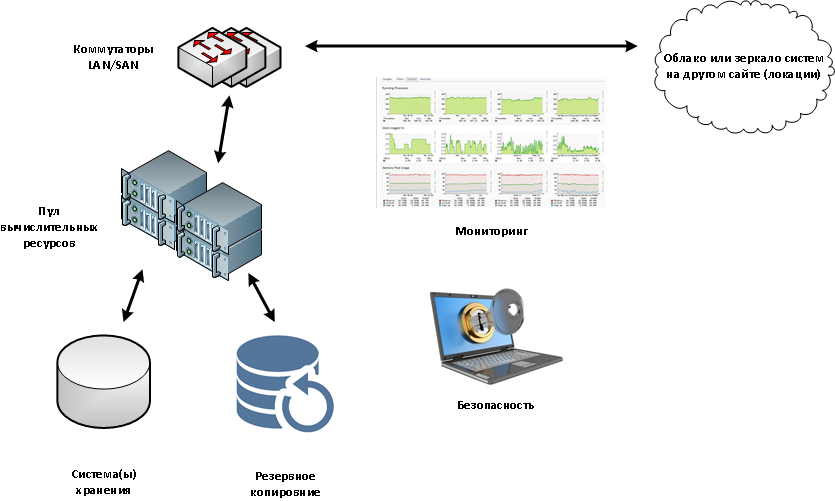
Кластерные системы могут быть высокоскоростные (High Performance), высокой доступности (High Availability), а также смешанные. High Performance используют для распараллеливания вычислительного процесса, High Availability – для максимальной отказоустойчивости.
Определяющими параметрами для кластерных систем высокой доступности (High Availability) являются:
Отказоустойчивость кластера обеспечивается дублированием всех компонентов системы. Идеальный кластер не должен иметь ни одного узла, выход из строя которого сделал бы систему неработоспособной (NSPF - No Single Point of Failure - отсутствие единой точки отказа).
Масштабируемость дает возможность подключения новых серверов без остановки всей системы.
Удобство обслуживания достигается возможностью проводить плановое техническое обслуживание и ремонт системы без ее остановки.
Преимущественно, мы предлагаем реализацию кластеров High Availability на базе Windows Server и высокопроизводительных серверов НРE. Но для нас не представляет никакой сложности реализовать кластеры на базе оборудования других крупнейших мировых производителей – Dell EMC, Lenovo/IBM, Fujitsu, Cisco.
Наиболее доступным и масштабируемым решением является построение кластера на основе виртуальных машин на платформе MS Hyper-V.
Для обеспечения бОльшей надежности все узлы кластера располагаются на различных физических серверах\узлах кластера.
С использованием средств онлайновой миграции со временем возможен перенос узлов кластера на новые, более современные физические серверы без потери работоспособности и без простоя любого узла.
Примеры проектов
1. SMB. Компания до 500 сотрудников на оборудовании HPE
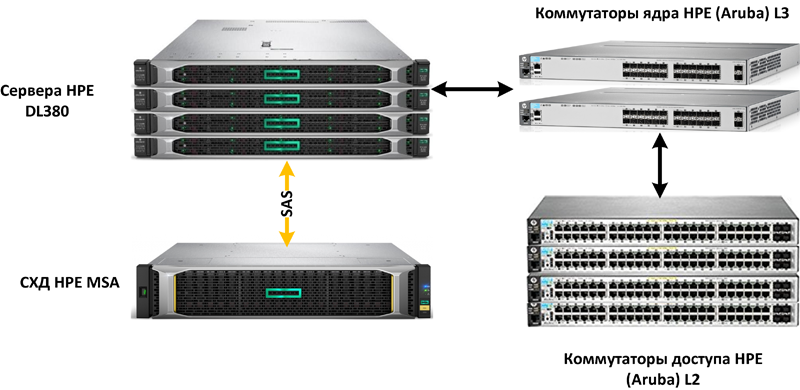
В данном примере представлен один из вариантов построения отказоустойчивой инфраструктуры для организации среднего бизнеса. Каждый компонент инфраструктуры зарезервирован. Дополнительно рекомендуется внедрение системы мониторинга.
Система хранения начального уровня позволяет подключить до 4-х серверов напрямую, дальнейшее расширение возможно с использованием iSCSI или построения 2-го кластера серверов.
2. Enterprise. Компания 2000 сотрудников на оборудовании Dell EMC
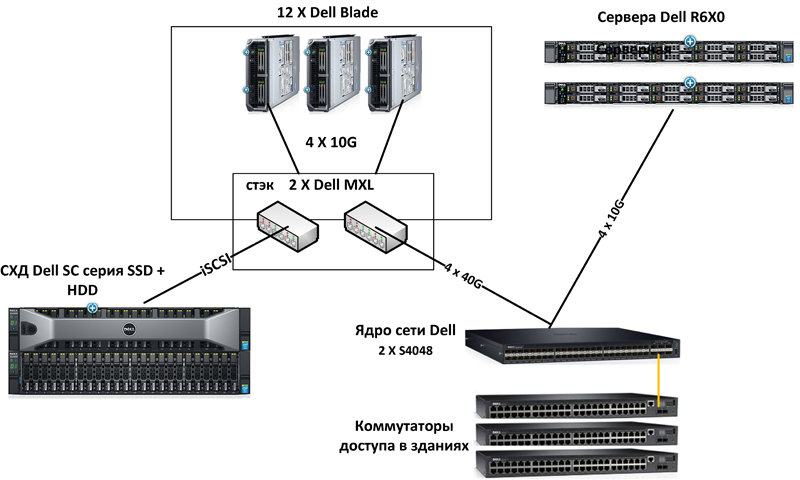
В данном примере рассмотрен вариант построения начального Enterprise решения для организации на 2000 рабочих мест с территориально распределенными ПК. Выбран вариант построения кластера на iSCSI как наиболее удобный для дальнейшего расширения.
3. Enterprise. Компания 5000 сотрудников на оборудовании HPE
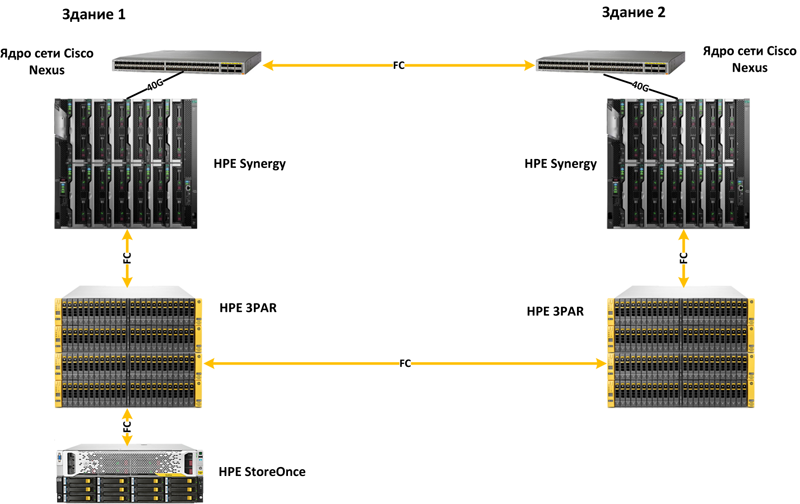
В данном примере рассмотрен вариант построения территориально распределённого кластера на базе оборудования HPE и Cisco. На двух площадках расположено идентичное оборудование, работающее в кластере с использованием синхронной репликации 3PAR. В решении также использована система резервного копирования.
